The version number provides means for network softfork upgrades. The previous block hash links the current block to its parent, creating the chain in “blockchain”. The Merkle root cryptographically ties all the transactions in a block to their associated header. The timestamp acts as a verifiable timestamping system, which is useful in many applications outside of Bitcoin. The encoded target difficulty lets the miner know what the network will accept as valid. And finally, the nonce provides a dedicated search space for the miners to mine, propelling the network forward.
This post aims to provide a technical overview of each of these fields with the intention of being a technical reference for the Bitcoin block header.
Introduction
Bitcoin’s blockchain is comprised of blocks. Blocks (and transactions) are versioned binary data structures. There are two parts to a block, the transaction block (where all the block’s transactions reside in their entirety), and the block header. The block header is a short and strictly formatted data field that prepends every block. It includes six fields, all with differing functionalities, and the SHA256d hash of these fields acts as the block’s identifier. The block header is the focus of this post and we will continue to dive into it in depth, but first let’s briefly touch on the transaction block.
When a network participant submits a new transaction to the network, it is appended to a list of all the other unconfirmed transactions. This list is called the mempool. Miners are the network participants responsible for choosing the unconfirmed transactions from the mempool to be included in the next block. This next block is called the candidate block. It is the miner’s responsibility to construct a valid block. A valid block is one whose block header hashes to a number that is less than or equal to a number set by the Bitcoin network, called the target.
The miner performs a large number of hashes in search of a valid block hash that meets the target requirement. In order to create new hashes from the same block data, a field in the header called the nonce field is dedicated for the miner to quickly change in order to generate unique hashes in the processes of finding a valid block. As will be further discussed, the nonce field only provides four bytes (2³² bits) that can be changed. Therefore, the search space is 2³² bits, meaning that up to 4,294,967,296 unique hashes can be generated for the block if nothing except for the nonce value is changed. While this may seem like plenty of search space, it is actually quite small given the Bitcoin ASIC hardware available today. For example, Bitmain’s Antminer S19 Pro ASIC miner performs at 110 Th/s. That is ~2⁴⁶ hashes per second. So, this machine completely exhausts the search space provided by the nonce field in under one millisecond.
Once the search space is exhausted, the miner must create a new block from a new set of transactions. Constructing this new block can be computationally expensive and bandwidth intensive. Therefore, miners have an incentive to find ways to expand the search space outside of the dedicated four-byte nonce. There are multiple ways of expanding the search space: miners can use (1) unused version field bits, (2) a portion of the time field bits, and (3) a few extra bits in the script signature of the coinbase transaction. The latter is generally referred to as the extranonce, although it is not a formally defined field in the Bitcoin protocol.
Like all data, transactions boil down to series of bytes. It is undesirable to have blocks that have too many bytes or are too “heavy” because of different resource constraints. The two more common constraints are (1) uplink related (bandwidth/latency), and (2) verification related (how fast the CPU can verify transactions). Storage related constraints are not as much of an issue now since storage has become rather cheap and nodes can prune. But larger blocks can deter space constrained individuals from running a full node, thus damaging network decentralization. Furthermore, without a block size limit, the network becomes susceptible to DDoS attacks from bad actors spamming low value transactions to the network. To combat these things, there is a consensus-imposed cap on the block size constraint called the block weight.
What motivates miners to mine blocks? They have two sources of revenue: the block subsidy (which will be discussed next), and transaction fees. It is a delicate balance for a miner to maximize their transaction fee profit by including as many transactions in the candidate block as possible, while also keeping the block weight under 4MB. This type of problem is akin to the knapsack problem , and it is of this author’s opinion that transaction selection is a fascinating problem, just not a glamorous one.
There is one special type of transaction called the coinbase transaction that is pertinent to the discussion of the block header. The coinbase transaction is included as the first transaction in every block and is responsible for minting new bitcoins (the block subsidy) and paying out the miner’s reward. As alluded to earlier, the malleable bits in the coinbase transaction are leveraged to increase a miner’s search space.
The Block Header
We are now ready to discuss the bitcoin block header. The header is 80 bytes and contains six different data fields, each in little endian format.
It is necessary to understand binary numbers, hexadecimal numbers, and endianness in order to be able to parse and understand block header and transaction contents. To explain these, a quick detour is taken in the proceeding subsection. If the reader is already familiar with these concepts, this section can be skipped.
Pertinent Number Systems & Endianness
Binary, Decimal, and Hexadecimal Number Systems
Integers are very commonly expressed with the base 10 number system, commonly called the decimal system. They can be equivalently expressed in any other base, however. The two other number systems that are useful in understanding these lower level Bitcoin concepts are binary numbers (base 2) and hexadecimal numbers (base 16). Changing the base from 10 to 2 or 16 (or any number for that matter) does not change the integer’s value, only how it is expressed.
Binary numbers are base 2, therefore only two values are needed to express the full range of integers. These values are 0 and 1. For example, considering the u8 type numbers (each number is 8 bits long):
| Base 10 | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|
| Base 2 | 0000 0000 | 0000 0001 | 0000 0010 | 0000 0011 | 0000 0100 |
Decimal and Binary Comparison
Note how much more verbose binary numbers are in comparison to the decimal numbers.
It is common to prepend the character “b” to a binary number. For example, the binary equivalent of the base 10 number 4 is equivalent is written as b0100.
You may be wondering why four digits are used to express, for instance, the binary number b0000 0001. Why not just b1? This is because in computer memory, you must choose the number of bits required for an integer ahead of time. So, if the integer may have to represent any number up to b1111 1111, then in memory the integer must always take up eight digits, even if it isn’t using all of the digits all of the time.
Putting an optional space in between every four zeros of a binary number makes it easier to read but holds no other significance.
Hexadecimal numbers are base 16, therefore 16 values are needed to express the full range of numbers. These values are 0–9 and A — F.
| Base 10 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Base 16 | 00 | 01 | 02 | 03 | 04 | 05 | 06 | 07 | 08 | 09 | 0A | 0B | 0C | 0D | 0E | 0F |
Decimal and Hexadecimal Comparison
Note how in this case, the decimal system is more verbose than that of the hexadecimal.
It is common to prepend the characters “0x” to a hexadecimal number. For example, the base 10 number 3,735,928,559 hexadecimal equivalent is written as 0xDEADBEEF.
Furthermore, note that 0xDEADBEEFis a four-byte number. Every two characters is equivalent to a single byte: 0xDE is one byte, 0xAD is one byte, and so forth.
For the sake of completeness, the decimal number 3,735,928,559 binary equivalent is b1101 1110 1010 1101 1011 1110 1110 1111.
Little Endian vs Big Endian
To give a taste for the concept of endianness, in English we say “23”, but in the German language they say “3 and 20”. It is the same number, just expressed differently. Endianness is a similar concept, big endianness orders the most significant digits first, and little endian orders the least significant digits first. The terms “big endian” and “little endian” is a reference to the book Gulliver’s Travels by Jonathon Swift . In the story, there were two groups of people, Big
Endian and Little Endian. The Big Endian group broke their eggs from the top, the Little Endian group from the bottom. Chaos ensues over this preposterous and insignificant difference in egg-breaking methodology.
At a lower level, endianness has to do with how a computer’s processor loads a value into its registers (memory). Namely, how the bytes are ordered.
In big endian format, the most significant bytes are read first. This is how we intuitively read numbers. The decimal number 3,735,928,559 written in big endian hexadecimal format is 0xDEADBEEF, exactly what one would expect. In a big endian formatted system, this number is stored in computer memory in binary as follows (the hexadecimal values are also presented for clarity):
| Base 2 | 1101 1110 | 1010 1101 | 1011 1110 | 1110 1111 |
|---|---|---|---|---|
| Base 16 | DE | AD | BE | EF |
Big Endian Formatted Binary and Hexadecimal Numbers
Alternatively, a number can be stored in computer memory using little endian formatting. In little endian format, the least significant bytes of the number are read first. This is not how numbers are intuitively read.
In a little endian formatted system, this number is stored in computer memory in binary as follows (the hexadecimal values are also presented for clarity):
| Base 2 | 1110 1111 | 1011 1110 | 1010 1101 | 1101 1110 |
|---|---|---|---|---|
| Base 16 | EF | BE | AD | DE |
Little Endian Formatted Binary and Hexadecimal Numbers
When comparing the big endian and little endian formats, it is (hopefully) clear that the only difference is the byte order. In big endian, the hexadecimal equivalent of 3,735,928,559 is 0xDEADBEEF. In little endian, the hexadecimal equivalent is 0xefbeadde. It is important to be aware of endianness because the little endian formatted number 0xEFBEADDE is still representing the decimal number 3,735,928,559, not the decimal number 4,022,250,974.
Remember, all of these numbers are equivalent, just expressed in different ways. For the most part, it does not matter if a system or program uses big or little endian, what matters is consistency.
Bitcoin (mostly) uses little endian format, and it is important to keep that in mind moving forward.
Back to the Block Header
Returning to the block header.
In its hexadecimal format, a typical block header looks like this:
 Bitcoin Block Header of Block at Height 645,536
Bitcoin Block Header of Block at Height 645,536
This block header is from the block at height 645,536 and was mined by Slushpool. It will be used as an example throughout this post.
Each field, its data type, and a very brief description is detailed in the following table.

How the Block Header is Used in the Mining Process
On a high level, the process of mining boils down the following steps:
1. Select a suitable version number and current epoch time. From the network, retrieve the previous block hash of the latest block on the
longest chain and the target.
2. Select a number of unconfirmed transactions from the mempool to include in the candidate block.
3. Construct the coinbase transaction.
4. Calculate the Merkle root from the coinbase transaction and selected transactions.
5. Concatenate these values to create the block message.
6. Select a number for the nonce and append it to the block message, creating the full candidate block header.
7. Perform the SHA256 hash on the block header (twice) and compare the result to the network target.
8. If the block header hash is less than or equal to the target, the
block is valid, and the miner propagates it to the network for
confirmation by their peers. They then return to step 1 and commence
mining on the next candidate block.
9. If the block header hash does not satisfy the target, the block is invalid and the miner returns to step 6, incrementing the nonce and trying their luck again.
These steps are detailed in the flowchart below.
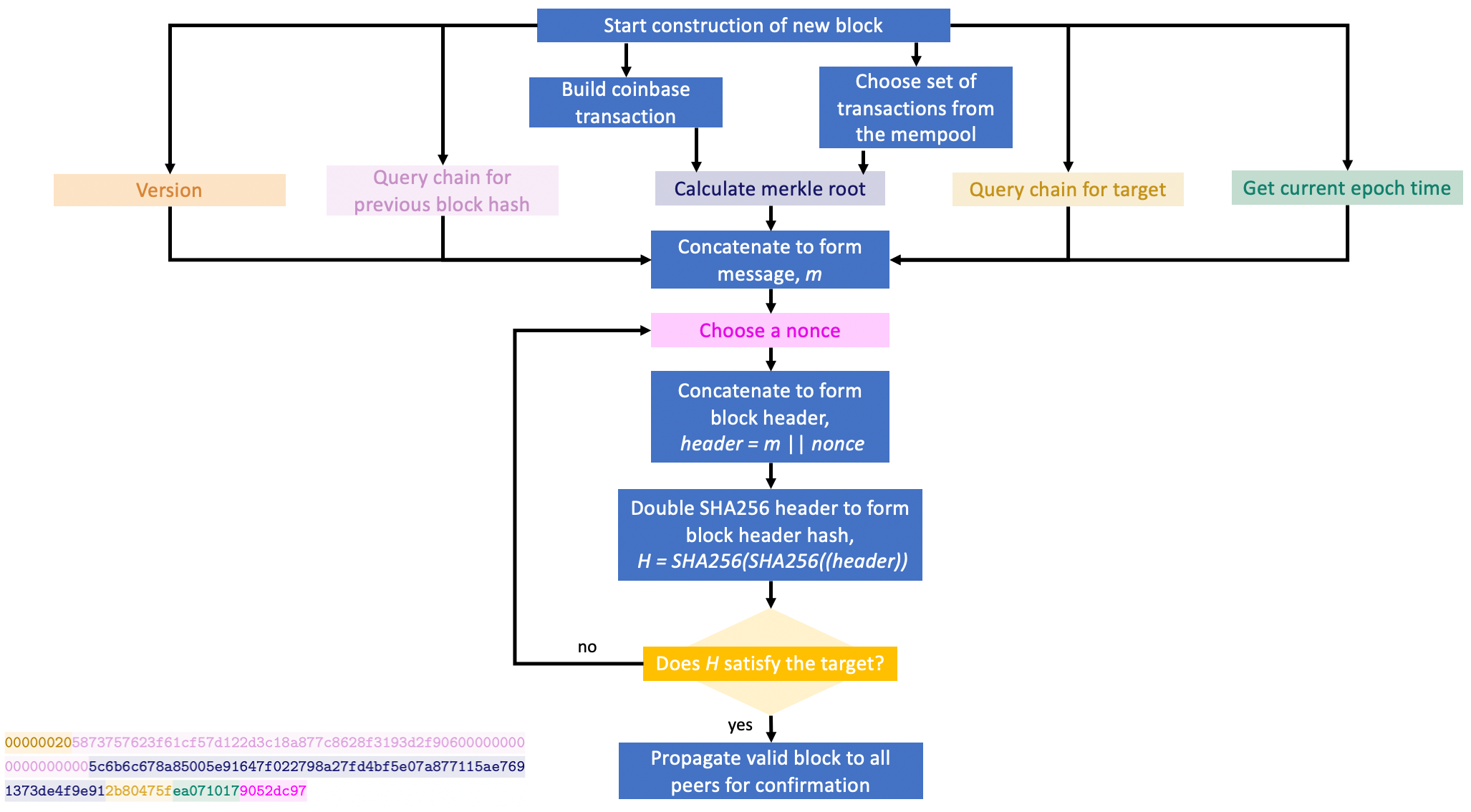 Flowchart of the Mining Process to Construct a Block Header
Flowchart of the Mining Process to Construct a Block Header
Now that the block header has been defined and the important role it plays in Bitcoin has been expressed, each parameter can be explored in more detail.
Version
 Version Field of Block at Height 645,536
Version Field of Block at Height 645,536
The version field is usually treated as a four-byte big endian number interpreted as type int32 and contains extra bits that miners can use to signal readiness for softfork proposals and for an additional search space of 2¹⁶.
For such an unassuming field, there is a lot to unpack when it comes to the version number of a block. The version number provides the means in which miners can signal their readiness for network softfork upgrades. The success or failure of a miner-activated softfork proposal is dependent upon if enough incoming blocks have signaled their readiness. Here, “readiness” means that the miner has updated their software to be compatible with the Bitcoin client release containing the proposed changes. An example of a softfork proposal is the segwit softfork.
The three most significant bits of the version fields are reserved for future possible mechanism upgrades. Currently, the three most significant bits must be set to b001. This means that the minimum allowed version number in big endian is 0x2000000 (b0010 0000 0000 0000 0000 0000 0000 0000). And the maximum version number in big endian is 0x3FFFFFF (b0011 1111 1111 1111 1111 1111 1111 1111).
At the time of writing this post, the version number behaves in accordance with the BIP9 specification. Before diving into BIP9, let’s take a look at how the version number has evolved since the birth of the network.
A Brief History of the Block Header Version Field
Version 1 started with the genesis block in 2009. Until September 2012, no meaningful signaling took place during this time.
In September 2012, Bitcoin Core v0.7.0 introduced BIP34 which rendered version 1 blocks to be non-standard. Specifically, this BIP did two things:
1. Give miners a structured way to signal readiness to accept a softfork proposal. This was achieved by the double-threshold switchover mechanism, also called IsSuperMajority(), which consists of two thresholds called the 75% rule and the 95% rule. The 75% rule states that once 750 out of the last 1,000 blocks signal readiness by setting their version 2 or greater, then any new blocks that specify version 2 in the block header must comply with the softfork proposal specification. Otherwise the block would be rejected by the network even if it was valid by version 1 standards. After this occurs, the 95% rule states that once 950 out of the last 1,000 blocks are version 2 or greater, then all version 1 blocks will be rejected.
2. Specify the actual soft fork proposal which requires all version 2 or higher blocks to include the block height as the first item in the script signature of the coinbase transaction.
It took around six months until version 2 blocks were the standard, with the last version 1 block at height 227,835 timestamped at 2013–03–24 15:49:13 GMT.
The softfork proposal defining version 3 is specified in BIP66 and was introduced in February 2015 in Bitcoin Core v0.10.0 . Version 3 blocks restrict signatures to strict DER encoding. The method to signal readiness followed BIP34.
The softfork proposal defining version 4 is specified in BIP65
and was introduced in November 2015 in Bitcoin Core v0.11.2
. Version 4 blocks recognized a new op code for the Bitcoin scripting system, OP_CHECKLOCKTIMEVERIFY, that allows UTXOs to be unspendable for a certain amount of time.
While the IsSuperMajority() signaling method specified in BIP34 worked, it did have some problems. Namely, (1) the lack of a timeout and (2) the use of integer values rather than bits for signaling (explained further below). BIP9 solved both of these issues.
BIP9 Version Field Improvements
BIP9 defines the version number behavior that is currently used. It requires that each softfork proposal have four parameters:
1. A distinguishing name.
2. A bit in the version field that when flipped signifies miner readiness. The number of the bit location is denoted by N.
3. A starttime that specifies when the selected bit gains its meaning.
4. A timeout, such that if the proposal has not been locked in by X date, it is deemed to be failed.
By flipping a single bit in the version field rather than setting the field to a specific integer number (as in BIP34), multiple proposals can be active at once.
Rusty Russell’s “BIP9: versionbits In a Nutshell” blog post does an exceptional job of explaining the development and significance of the version field. We will build off this post and continue to explore the version field in detail. Let’s start by examining exactly how the bit flipping specified in BIP9 works.
The full 32-bit binary representation of the typical big endian version number of 0x20000000 is expressed as
b0010 0000 0000 0000 0000 0000 0000 0000
This follows the rule set in BIP9 that the topmost bits must be b001 or greater.
Now, let’s say there is a new soft fork proposal called BIPN₀ that sets the readiness bit location to 0 (N = 0), requiring that the 0ᵗʰ bit be set to 1 for the miner to signify readiness. The version number in big endian would then be 0x20000001, or
b0010 0000 0000 0000 0000 0000 0000 0001
This miner has now signaled their readiness for BIPN₀.
Now, let’s say there are simultaneously two additional soft fork proposals active. BIPN₁ (N = 1) and BIPN₂ (N = 2). Perhaps this miner is only ready for BIPN₀ and BIPN₂, not BIPN₁. With the BIP9 mechanism, this is not an issue. The miner would signify readiness for only BIPN₀ and BIPN₂ by setting the 0ᵗʰ and 2ⁿᵈ bits to 1 and leaving the 1ˢᵗ bit as 0. The version number in big endian would then be 0x20000005, or
b0010 0000 0000 0000 0000 0000 0000 0101
The ability to have multiple soft fork proposals active at any given time makes this mechanism superior to BIP34’s use of integer values.
Miners can and do use this the version field to gain extra search space. This is called overt ASIC boost via version rolling. Initially after BIP9 was introduced, miners were still using all the version bits to perform an overt ASIC boost. However, this resulted in nodes generating warnings as they were trying to interpret the bits as a signaling for a non-existent softfork proposal. BIP320 solved this issue by designating 16 bits for overt ASIC boosts, and by leaving 13 bits open for softfork proposal signaling. This gives the miner a search space of 2¹⁶ and leaves room for 13 simultaneous softfork proposals.
Previous Block Hash
 PrevHash Field of Block at Height 645,536
PrevHash Field of Block at Height 645,536
The previous block hash field is a little-endian formatted 32-byte value interpreted as type char[32] that is the hash of the previous block. This field is what provides the link between the current and previous block in the network.
Merkle Root
 Merkle Root Field of Block at Height 645,536
Merkle Root Field of Block at Height 645,536
The Merkle root field is a little-endian formatted 32-byte value interpreted as type char[32]. The Merkle tree structure is used throughout the field of computer science for numerous purposes. In Bitcoin, a Merkle tree is used to cryptographically tie each transaction that is in the transaction block to the block header in a succinct 32 bytes.
Each transaction is a leaf of the Merkle tree. The transactions must be included in topological order. Meaning, when txₙ₊₁ spends an output of txₙ, txₙ₊₁ must be sorted to a later position in the block than txₙ.The very first leaf in the Merkle tree. This first leaf, tx₀, is reserved for the coinbase transaction.
Finding the Merkle Root
Once a miner has selected the transactions to include in the candidate
block, the following steps are performed to derive the Merkle root:
1. In pairs of two, each transaction id (SHA256d hash of the transaction) is concatenated together.
2. The concatenated transaction pair is hashed via the SHA256d hashing algorithm. The digest of this hash becomes a new branch in the tree.
3. Again, in pairs of two, the digests are concatenated together and hashed via the SHA256d algorithm producing a new branch in the tree.
Step 3 is repeated until only one hash remains, the Merkle root hash, which is the value stored in the block header.
 Merkelization of an Arbitrary Dataset
Merkelization of an Arbitrary Dataset
Time
 Time Field of Block at Height 645,536
Time Field of Block at Height 645,536
The time field is a little-endian formatted four-byte value interpreted as type uint32 that is the epoch timestamp of the current block. The job of the timestamp is to provide means for the network to determine how fast blocks are being confirmed so it can adjust the difficulty every 2,016 blocks (about 2 weeks). Consensus rules constrain the range of accepted timestamp values to about a three-hour window, leaving 2¹³ bits that can be used for extra search space.
A valid timestamp must be greater than the median timestamp of the previous 11 blocks. At a confirmation rate of 10 minutes per block, this is one hour from the submission time of the candidate block. The timestamp must also be less than the network-adjusted time plus two hours. This three-hour window is 10,800 seconds which yields 2¹³ extra bits of search space by
2ˣ = 10,800
x = ln(10,800) / ln(2)
x = 13.3987 => 13
The network-adjusted time is the node-local UTC plus the median offset from all connected nodes. Network time is never adjusted more than 70 minutes from local system time.
An unintended but useful consequence of including the timestamp field in the block header of a healthy decentralized network is that the Bitcoin blockchain can be used as an effective time stamping tool.
Bits
 Bits Field of Block at Height 645,536
Bits Field of Block at Height 645,536
The bits field is a little endian formatted four-byte value interpreted as type int32 that encodes the current target threshold in a compact four-byte field. The resultant block hash must be under the target in order to be considered a valid solution by the network. The target is updated every 2,016 blocks (roughly two weeks), so every block header submitted during the 2,016-block time frame will have the same target value encoded in the header.
As we know, to find a block hash, the block header data fields (the version, previous block hash, Merkle root, target, time, and nonce) are all concatenated and hashed together via the SHA256d hashing operation. The resultant hash is the candidate block’s header hash and acts as a unique identifier for this block. In order to be considered valid, the hash must be less than or equal to the current network target which reflects how easy or difficult it is for a miner to mine a valid block. Without the target, it would be effortless to create a valid block and the network would fracture and fall apart.
The maximum target produced by a SHA256d hash is 0x00000000FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF or in base 10, 26,959,946,667,150,639,794,667,015,087,019,630,673,637,144,422,540,572,481,103,610,249,215. This is a very big number. Bitcoin stores the target as a floating-point type, so the truncated form used is 0x00000000FFFF0000000000000000000000000000000000000000000000000000, which again in base 10 is 26,959,535,291,011,309,493,156,476,344,723,991,336,010,898,738,574,164,086,137,773,096,960. This is still a huge number.
In order to fit this large number into a four-byte space it uses a compact format. This format sacrifices granularity for byte space. The following steps detail how to retrieve the target from the bits value.
1. Swap endianness from little endian format in the block header, to big endian, 0x2F931D1A → 0x1A1D932F. Ultimately it does not matter the endianness used as long as everything stays consistent.
2. Separate the first byte, 0x1A, from the remaining bytes, 0x1D932F. This first byte is called the mantissa (also called significand). The mantissa is the part of a floating-point number that represents the number of significant digits. It is then multiplied by the base, which in this case is 2, and raised to the exponent to give the value of the number.
Therefore, the target threshold is extracted from the bits field by:
Target = Mantissa × Base⁽ᴱˣᵖᵒⁿᵉⁿᵗ ⁻ ᴸᵉⁿᵍᵗʰ ᵒᶠ ᴹᵃⁿᵗᶦˢˢᵃ⁾
Using this equation, the target threshold for this block is found by:
Target = 0x1D932F × 2⁽⁸ˣ⁽⁰ˣ¹ᴬ ⁻ ³⁾⁾
= 0x1D932F × 2⁽⁸ ˣ ⁽²⁷ ⁻ ³⁾⁾
= 0x1D932F0000000000000000000000000000000000000000000000
Note that the difference between the exponent and the length of the mantissa is multiplied by 8 in the above equation. This is a slight short cut, leveraging the fact that there are eight bits in one byte. So instead of writing each of the parameters out in binary, which would be much more verbose, each byte is taken in its entirety.
3. The result of step 2 can now be compared to the header hash. If the header hash is equal to or below the target threshold, it satisfies the Bitcoin consensus rules and can be confirmed on chain.
0x0000000000001D932F0000000000000000000000000000000000000000000000
0x00000000000016BF116FC90CF45AEC2DA4D13349358159D8B4EDDCB37EAB295B
Writing the numbers in their equivalent base 10 form looks like:
47525089675259291211422247200069659468817014361857087365971968
36551990950853533658225321687497789580066641734434828845787483
Therefore, since the header hash value is less than the target, this is a valid header.
Let’s explore a little deeper as to why this formula was chosen and how it works. The format itself originates from the IEEE 754 standard for floating-point arithmetic which just details how computers store floating-point numbers.
Consider a 16-bit register containing the number 11:
b0000 0000 0000 1011
A 16-bit register only has space for, you guessed it, 16 bits. If we shift the bits over by the number of available bits (16), we encounter an overflow and lose our number 11:
Lost Bits | Remaining Bits
1011 | 0000 0000 0000 0000
To prevent this from happening we impose that we can only shift by our available bits minus the number of bits we want to make sure we keep. In this case, 16 – 4 = 12, which would yield
Lost Bits | Remaining Bits
|1011 0000 0000 0000
So, that is why we subtract the number of bytes from the exponent when calculating the target: to prevent against edge cases where the exponent would cause an overflow and we would lose significant digits of our mantissa.
Nonce
 Nonce Field of Block at Height 645,536
Nonce Field of Block at Height 645,536
The nonce field is a little endian formatted four-byte value interpreted as type int32 that is incremented in order to create a new hash of the current block with the intention of finding one that meets the current target. It provides 2³² bits of search space.
The nonce parameter plays an essential role in finding a valid block. Without the nonce, every single time a miner constructs a block that did not meet the network difficulty, they would have to modify the transaction set, recalculate the Merkle root, rebuild the block header, and rehash. This requires a non-negligible amount of computational work. The nonce makes it such that the miner only needs to construct the block header candidate once, keeping all the variables constant except for the nonce. The miner will increment the nonce and then rehash the block until (1) the block header hash either meets the difficulty target (they found a valid block header), (2) the block becomes stale (a competing miner found a valid block header), or (3) they run out of nonce search space.
The Coinbase Transaction
Coinbase transaction is a special type of transaction in every bitcoin block — the only transaction that does not point to an existing UTXO, but instead mints new bitcoin according to the bitcoin protocol monetary policy.
The coinbase transaction is important for three main reasons: (1) it is
responsible for minting new UTXOs, (2) it provides extra search space to the miner, and (3) it provides the miner with the means to tag a block as their own.
The coinbase transaction for block 645,536 is the following:
 Coinbase Transaction of Block at Height 645,536
Coinbase Transaction of Block at Height 645,536
Each field, its datatype, and a very brief description is detailed in the following Table.
 Transaction Data Fields
Transaction Data Fields
For the purposes of this post, the script signature is the field of importance because it is where the miner gains extra search space and also where the miner can put in their identifier.
Script Signature (Unlocking Script)
 Script Signature in the Coinbase Transaction of Block at Height 645,536
Script Signature in the Coinbase Transaction of Block at Height 645,536
The script signature, also called the unlocking script, is of variable byte length which is capped by consensus. Typically, the unlocking script contains conditions that allow the consumption of the previous transaction’s UTXO. In the coinbase transaction, however, there is no UTXO being consumed, only new UTXOs being minted. Instead, the script signature contains the block height (as specified by BIP34) and any other information the miner chooses to put here. Very commonly this includes any extranonce parameters and any identifying “signatures” that the miner may optionally include.
The extranonce parameter is not a strict field defined by the Bitcoin protocol, but rather some bits that the miner can optionally use to increase their search space. Many pools support the extranonce parameter and put restrictions on its length. It is common to see an eight byte extranonce.
Breaking down the script signature, the first 1–9 bytes indicates the length of the unlocking script which is of variable. In this case, the length is 0x4B (decimal 75) bytes.
The next byte indicates the length of the next portion of the coinbase transaction. In this case, it is 0x03, which indicates that the next three bytes, 0xA0D909, are of significance. These bytes are the block height of 645,536 in little endian hexadecimal format in accordance with BIP34. The next 64 bytes contain the extranonce parameter(s) and any other information the miner chooses to put there. The size of the extranonce parameter typically varies from pool to pool.
Finally, the last seven bytes, 0x2F736C7573682F is the optional identifier that Slushpool uses for their blocks, /slush/. By providing this identifier, Slush is making it publicly known that this block came from their pool.
Of course, any entity could put this same text in the coinbase transaction and pretend to be Slushpool (or any other miner). And, conversely, Slush (or any other miner) could exclude their typical identifier from the coinbase script signature and anonymously mine the block.
This identifier is optional for any miner to put in their designed characters. Most of them normally put their name to show they are mining blocks (which makes sense from marketing perspective to show how successful your pool is) but a miner can put whatever they want or leave it empty. To get a feel for how many miners include an identifier in the script signature of the coinbase transaction, 77.7% of blocks included an identifier over the four-day time span from September 25ᵗʰ, 2020 through September 28ᵗʰ, 2020.
Conclusion
Understanding the block header is essential to understanding mining and Bitcoin as a whole. The block header plays many important roles in the Bitcoin protocol, each of its six fields working together to form the backbone of the network.
The block header is the avenue by which all the transactions in a block are linked together via the Merkle root, and further link that block to its parent with the previous block hash, creating the chain. The version number is used by miners for protocol upgrade support and readiness signaling. The encoded target difficulty lets the miners know what the network will accept as valid, and the nonce provides them with a dedicated search space for the valid hash.
The block header is exceptional in its simplicity, yet full of applications and use cases. While its format has held up for over a decade now, it still is flexible enough to adapt as the network changes and grows. How fields operate can and does change for the better, as seen with the softfork upgrading mechanism defined by the version field. How fields are used changes as well, as seen with how miners can use nontraditional fields to accommodate more search space via the version, timestamp, and coinbase transaction. The creativity of the bitcoin developers and users in leveraging the block header and its associated fields to accomplish more and enable new use cases, is astonishing, and we cannot wait to see what the next decade of innovation brings us. But whatever it is, we are certain that the block header will be the backbone of this beautiful system.